How to Restore Website Content Using archive.org
Disclaimer: the following steps can help gather/rebuild from cached static images of your website from the Internet Archive. This procedure may give you a starting point in rebuilding your website.
Also, there is no guarantee that the Internet Archive will have cached your website files. Following the below steps should only ever be an alternative to restoring an actual backup of your website.
What is the Internet Archive?
The Wayback Machine (web.archive.org) is a digital archive of the World Wide Web. Since its launch in 2001, over 452 billion pages have been added to the archive. Users can enter a URL to view and interact with past versions of any website contained in the Archive, even if the site no longer exists on the "live" web.
Procedure:
- In a browser, navigate to the Internet Archive
- Enter the full URL of your website (e.g. example.com/index.html)
- Press enter or click the Browse History button
- On the next page, you’ll see a calendar displaying all cached copies of your webpage
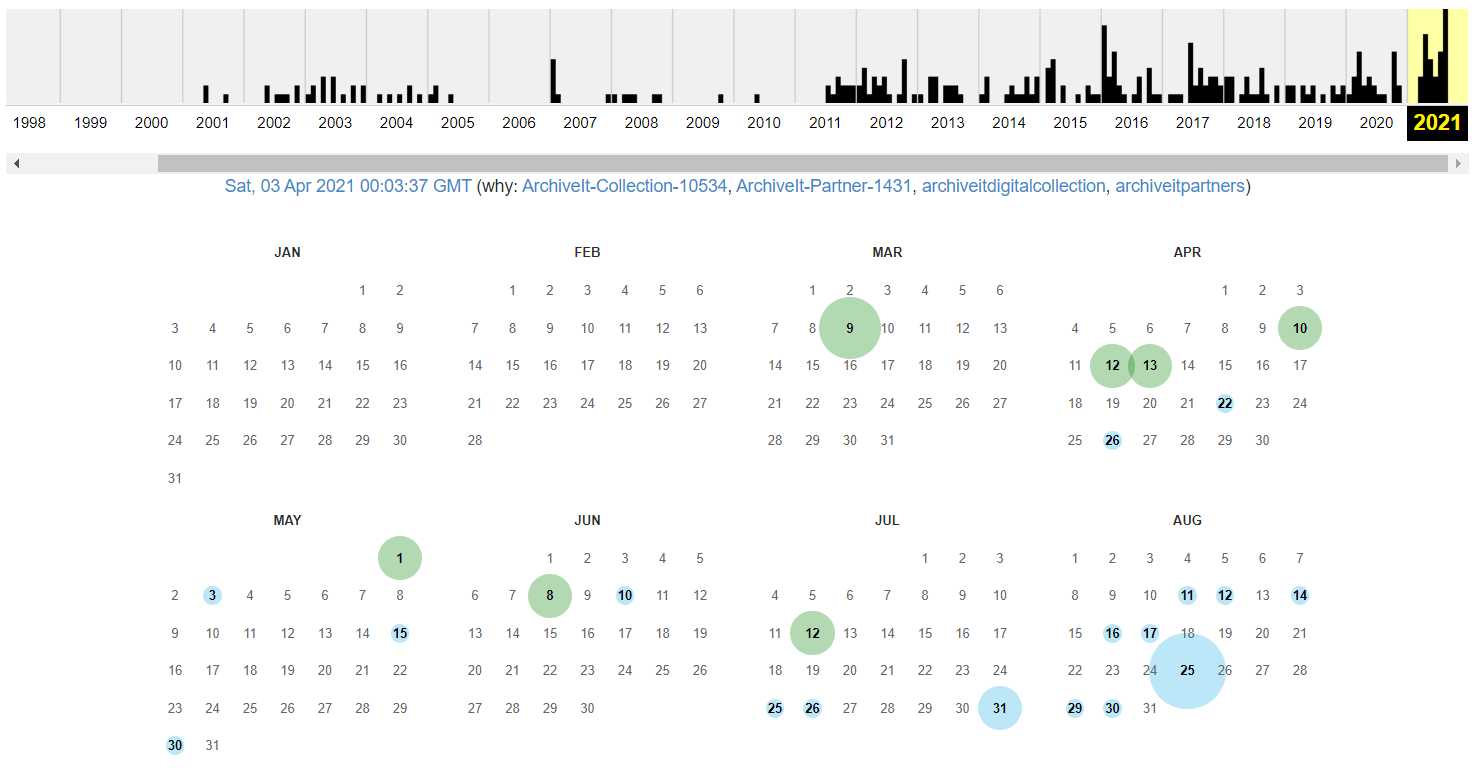
- You can click on a date to open a cached version of your webpage, then click the time from the available snapshots
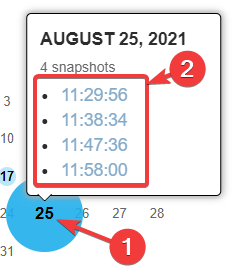
- Your cached page will open so you can obtain the source code (in most browsers simply right-click and select View Page Source). Copy the code and paste it into a text editor, then save it as an HTML file and upload to your server (see Publish a Site From your Computer), ensuring you have renamed the file as the page you are replacing.
